/image%2F0796222%2F201310%2Fob_2c9ac248b841c2bc6f22aeb3f1b3a82b_marseille.jpg)
DUMP et DUMP en UTF-8
Publié le 20 Novembre 2013
Une fois les pages aspirées, il faut quand même bien en faire quelque chose. Pour cela on va créer un DUMP c'est a dire un fichier qui ne contient que le texte de notre page (principe déjà abordé dans le billet précédent) .
Pour que nous puissions exploiter ces DUMPs correctement, il faut s'assurer de l'encodage des pages. Ainsi, pour que la tâche soit plus simple, nous allons choisir de les avoir en UTF8. Cela nous mène a deux possibilités:
- soit la page est déjà en UTF8, et dans ce cas on la garde tel qu'elle est;
- soit la page n'est pas en UTF8, au quel cas on va se charger de la convertir en UTF8 et de faire en sorte de l'enregistrer comme telle.
Mine de rien, tout ce processus est bien plus lourd qu'il n'y parait, et comme d'habitude, il faut constamment faire attention aux petites fautes bêtes, comme les espaces, les guillemets, les points et etc...
Une fois le programme lancé, les commandes exécutées et les premiers messages d'erreur repérés, il est temps de comprendre ce qui a planté!
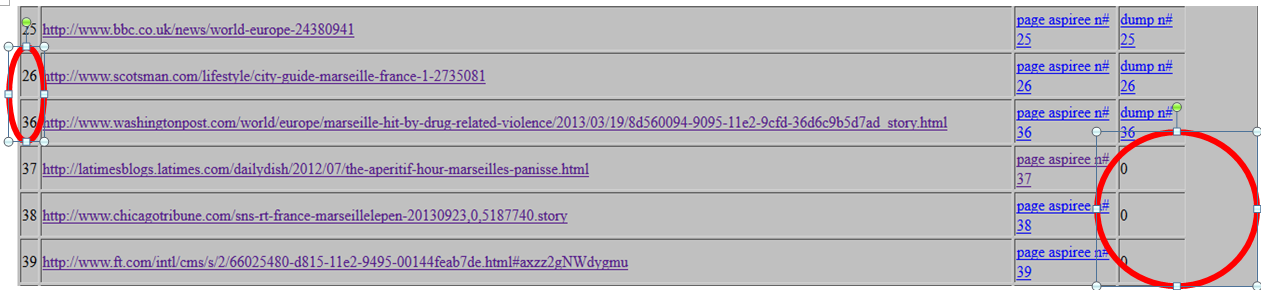
En tête de ligne (c'est le cas de le dire), un problème de saut de fichiers pour ce qui est des pages aspirées (voir la colonne de gauche sur le screenshoot). Explication: le problème vient tout d'abord des pages aspirées, l'aspiration ne se faisant pas correctement, il ne peut bien évidement pas retrouver la page pour pouvoir la traiter en DUMP puis en DUMP UTF-8, il est donc nécessaire de comprendre d'où vient se problème pour ensuite avoir de la matière à analyser!
Deuxième problème, une absence pure et simple de DUMP de quelque nature que ce soit! Explication: le lien fonctionne correctement, la page aspirée est viable, MAIS, lorsqu'il s'agit de lire le DUMP, un magnifique message d'erreur s'affiche: "400 BAD REQUEST". Merveilleux. Pour le moment nous ne savons pas encore s'il s'agit du traitement qui a été fait sur les pages ou si c'est un problème de la page elle même. A suivre donc.
Enfin, dernier problème, mais pas des moindres: nous nous sommes rendues compte que certains journaux sont quelques peu récalcitrant à l'idée de nous laisser faire un DUMP sur leurs pages! Cela peut être du à une intolérance du browser, au fait que le site à mis une "option" sur la fréquence à la quelle une adresse IP peut lire une de ses pages, et il doit bien avoir d'autres soucis, mais ça donne déjà un petit aperçu. En tous cas, l'une des solutions possibles - probablement la plus simple - est de traiter toutes les URLS concernées à part, dans un autre fichier, ou alors de faire leur traitement de manière manuelle et d'incorporer le résultat du travail à la suite de ce qui a déjà été fait automatiquement.
Encore une fois, à la fin de cette séance de travail, on voit bien que le travail est loin d'être terminé! Pourtant il va bien falloir résoudre rapidement ces "petits" problèmes puisque nous allons commencer le traitement linguistique des textes sous peu!
Au programme pour la prochaine fois? Résolution (ou au moins explication) de tous les problèmes et tracas préalablement cités + une ou deux colonnes supplémentaires: une pour l'index des mots et une autre pour leur contexte.
Encore une fois: tout un programme!!!